

Sé lo que estáis pensando: «¿Web Scraping? ¿Rubíes? ¿Nokoqué? Este hombre nos está hablando en chino.» Que no cunda el pánico, en este artículo arañaremos la superficie de un tema del que poco se habla y programaremos nuestro primer scraper.
¿Que qué es el web scraping?
Web scraping es una técnica utilizada mediante programas de software para extraer información de sitios web. Usualmente, estos programas simulan la navegación de un humano en la World Wide Web ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación.
Tabla de Contenidos
Si eres un desarrollador web puede que esta pequeña guía sea un poco simple para ti, sin embargo puede que alguna de las ideas que comentamos te sean bastante útiles. Los que no hayáis escrito nunca una sola línea de código no tenéis de que preocuparos, la guía es completamente noob-friendly y quien sabe, quizás os gusta esto de la programación 😉.
Cuando navegamos por la red se nos presenta información en forma de documentos HTML. Todos los sitios webs siguen una estructura y un etiquetado interno que no podemos observar a simple vista, sin embargo existen multitud de posibilidades para aprovechar todas esa información y exportarla a una hoja de cálculo o una base datos.
El scraping web nos permite recopilar información estructurada de un sitio web cuando este no dispone de una base datos pública,un feed RSS o una API.
El Lenguaje de Programación Ruby

En el panorama del desarrollo web Ruby (en conjunto con Rails) es uno de los lenguajes de programación más utilizados. Otros lenguajes muy utilizados son PHP, Javascript y Python, por lo que si queréis iniciar vuestro camino para convertiros en un desarrollador web haríais bien en empezar por uno de ellos 😎. Una de las ventajas que poseen estos lenguajes es que tienen a sus espaldas unas comunidades de usuarios increíbles, los cuales generan multitud de librerías que facilitan la vida al programador novato.
Cada lenguaje tiene sus pros y sus contras y un buen desarrollador tendría que saber desenvolverse en todos ellos. Por ejemplo, si utilizásemos Javascript podríamos aprovecharnos de su carácter asíncrono para acceder a información que normalmente estaría bloqueada hasta que el cliente la libera por alguno acción del usuario (esto puede ser una página que carga el contenido a medida que el usuario hace scroll vertical).
A pesar de que Javascript se ha convertido recientemente en el lenguaje de moda, tanto para el front-end como en en el back-end, Ruby se adapta mucho mejor al carácter básico de este artículo. Además de poseer una gran comunidad,y ser un lenguaje de programación versátil y perfecto para principiantes viene instalado por defecto en los ordenadores Mac y es realmente sencillo de instalar en sistemas Linux.
Nuestar pequeña Gema: Nogokiri
Nokogiri es una Gem de Ruby, es decir, una extensión o librería creada por otro usuario y que incluye funciones listas para su uso, lo que nos ahorra un montón de trabajo y permite que cualquier novato pueda programar cosas bastante interesantes.
Básicamente, Nokigiri transforma un sitio web en un Objeto Ruby lo que hace que todo esto del scraping web sea pan comido💪. Este trabajo se lo tenemos que agredecer a Aaron Patterson y Mike Dalessio, así que ya sabéis, si algún día os los encontráis por ahí invitadles a unas cañas 😁.
Si os a picado el gusanillo de la programación os recomiendo echarle un ojo a la famosa Code Academy. Tenéis a vuestra disposición multitud de tutoriales paso a paso perfectos para novatos ✌️.
¿Para qué nos sirve el Web Scraping?
Comprender como funciona un scraper (algo que a priori suena muy complejo) nos hará dar un paso hacia delante en nuestra carrera para convertirnos en un mejor online marketer no me sale el término en castellano 😅. ¿Y qué mejor manera de entender un scraper que programando uno nosotros mismos?
En el sector del marketing online la información es vital, por lo que ser capaz de extraer fácilmente información de cualquier web es una baza increíble que añadir a nuestro arsenal personal. Supongo que ya estaréis ansiosos por empezar, aún así os voy a dejar unas cuantas aplicaciones prácticas de lo que vamos a aprender hoy para inspiraros un poco.
Aplicaciones Seo
En el mundillo del Seo se lleva sacando provecho a los scrapers desde casi sus inicios y han surgido muchas herramientas y productos que basan su funcionamiento en esta técnica.
Black Hat
Ay el Black Hat amigos míos… Qué blackhatter que se precie no a dedicado unas cuantas horas de su vida a scrapear la red 😈. El único límite es el ingenio y la imaginación de cada uno. Contenido, enlaces autoaprove, keywords… Todo lo que podáis soñar está en el lado oscuro del Seo, aunque debéis tener en cuenta el riesgo que implica si no queréis salir perjudicados de vuestras pequeñas maldades.
Automatizar auditorías
Screaming Frog es un claro ejemplo de como el web scraping puede ahorrarnos horas y horas de trabajo. En unos segundos podemos obtener todos los tags, etiquetas, titles… de un sitio web, trabajo que, manualmente, sería irrealizable.
Aplicación en Marketing Digital
No todo es Seo en el mundillo, los marketers más puros también pueden sacar provecho a estas técnicas.
Recopilar Inmensas Cantidades de Datos
En el mundo 2.0 se come y se respira información. Los datos son necesarios para analizar mercados, encontrar oportunidades de negocio, elaborar gráficas… Normalmente estábamos limitados a la información pública y a lo que las APIs nos permitían obtener, el web scrapping nos abre todo un nuevo abanico
Aplicación a un E-commerce
Los e-commerce pueden sacarle mucho jugo a este tipo de herramientas, ya que les permiten comparar sus propias bases de datos con las de la competencia rápidamente.
Recopilar Información sobre la Competencia
¿Cuáles son los productos más vendidos de nuestra competencia? ¿Los que más valoraciones positivas reciben? ¿Y cuáles generan más interacciones sociales? Podemos recopilar y organizar toda esta información fácilmente.
Comparación de Catálogos
Los grandes e-commerce del sector como Amazon utilizan constantemente scrapers que recorren la web en busca de precios, en función de los cuales actualizan los suyos propios para obtener así precios competitivos en tiempo real. Una tienda online común puede aplicar la misma técnica pero a una escala mucho más reducida (pero no por ello menos efectiva).
Programando nuestro Scraper
Ha llegado el momento, es hora de ponernos manos a la obra y de empezar a programar. Como os he comentado hace poco, una de las ventajas que nos ofrece scrapear un página es que no necesitamos ningún tipo de API, por lo que páginas que antes eran inaccesibles ya no lo son. Estoy seguro de que conocéis uno de los casos más famosos de Growth Hacking como es el de AirBnB y su implementación de Craiglist. Para este primer scraper vamos a intentar emular a muuuuy pequeña escala el trabajo de los chicos de AirBnB, para ello vamos a extraer todos los anuncios de viviendas en Madrid que incluye la web (podríamos extraer cualquier tipo de anuncios de cualquier localidad, pero me apetece mantener la metáfora 😏)
Preparando el Terreno
Para poder completar todo el proceso tendréis que cumplir una serie de durísimos requisitos:
- Un ordenador con Ruby instaldo.
- Un editor texto.
- Conocimiento básico sobre HTML y CSS.
Si tenéis un Mac es probable que Ruby venga instalado por defecto con el sistema, por lo que un problema menos. Los usuarios de Linux lo tendrán más o menos complicado dependiendo de la distribución que utilicen. En el caso de Ubuntu el proceso es tan simple como ejecutar desde la consola la siguiente instrucción:
$ sudo apt-get install ruby-full
A los usuarios de Windows os remito a la página oficial de Ruby para resolver vuestras dudas.
Como editor de texto yo utilizo y recomiendo Sublime Text, el cual incluye un buen puñado de funcionalidades que hacen la experiencia de programar mucho más sencilla.
Un poco de HTML y CSS hay que aprender a la fuerza si no quieres ahogarte en esto del marketing digital. Si tenéis alguna duda siempre podéis acudir a W3Schools para solucionarla (o dejarla por los comentarios 😉).
A continuación tenemos que instalar las 3 Gems que utilizaremos: Nokogiri, HTTParty y Pry.
En el caso de Ubuntu y de ordenador Mac es tan simple como ejecutar tres comandos desde la terminal:
$ sudo gem install nokogiri
$ sudo gem install httparty$ sudo gem install pryHTTParty nos servirá para enviar una solicitud HTTP al sitio web mediante la función get(). Esto nos devolverá todo el HTML de la página en formato String.
Pry es una de las mejores herramientas de debuggin con las que cuenta Ruby (o al menos una de mis favoritas). Nos ayudará a entender mejor cómo funciona nuestro código a lo largo de esta guía.
Crear nuestro archivo
Abrimos nuestro editor de texto favorito y creamos un nuevo archivo llamado scraper.rb (podéis ponerle el nombre que os apetezca).
A continuación añadimos todas las dependencias que necesitaremos mediante «require».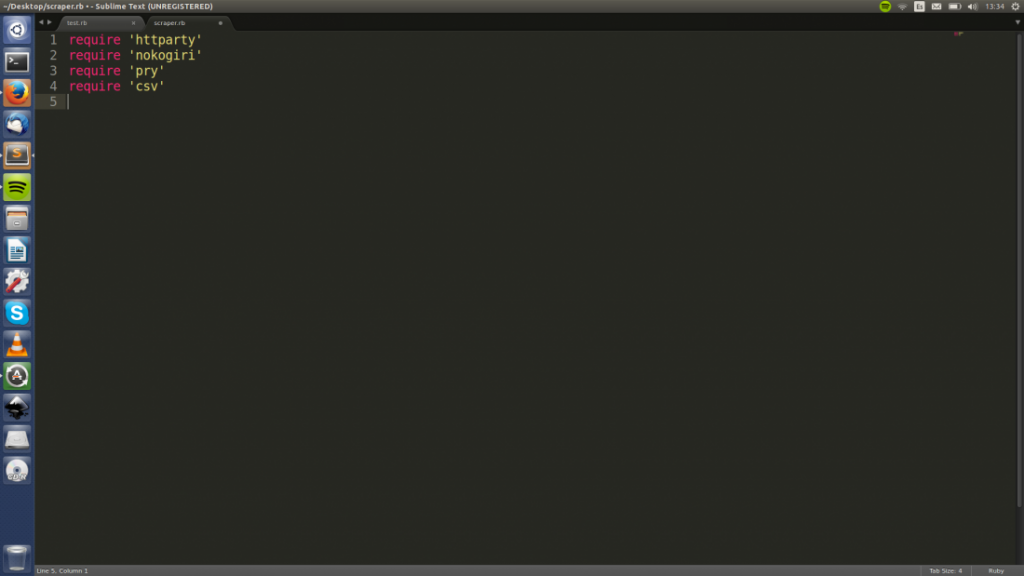
Enviar una solicitud HTTP
Creamos una nueva variable llamada página y le asignamos el valor de la función HTTTParty.get(«aquí va nuestra url»), con lo que obtendremos el código HTML de la página.
A continuación escribimos Pry.start(binding).
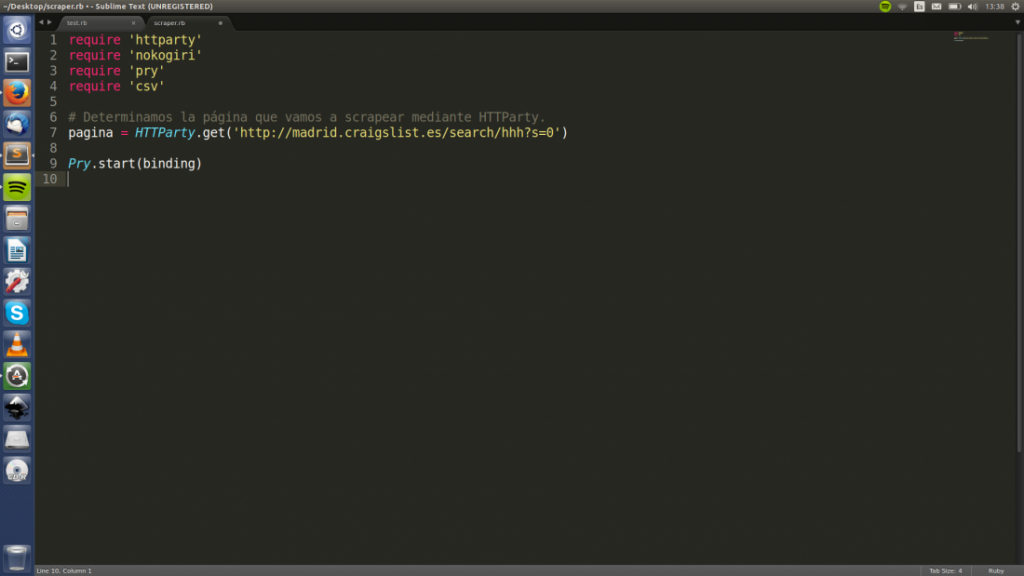
A continuación abrimos nuestra terminal y navegamos hasta el directorio en el que se encuentra nuestro archivo. Si habéis guardado vuestro archivo en una carpeta llamada seoconbarba situada en el escritorio tendréis que ejecutar:
cd Desktop
cd seoconbarba
A continuación ejecutamos nuestro programa mediante el comando:
ruby scraper.rbSi escribimos «pagina» en nuestra terminal imprimiremos el código HTML de la página de Craiglist en cuestión.
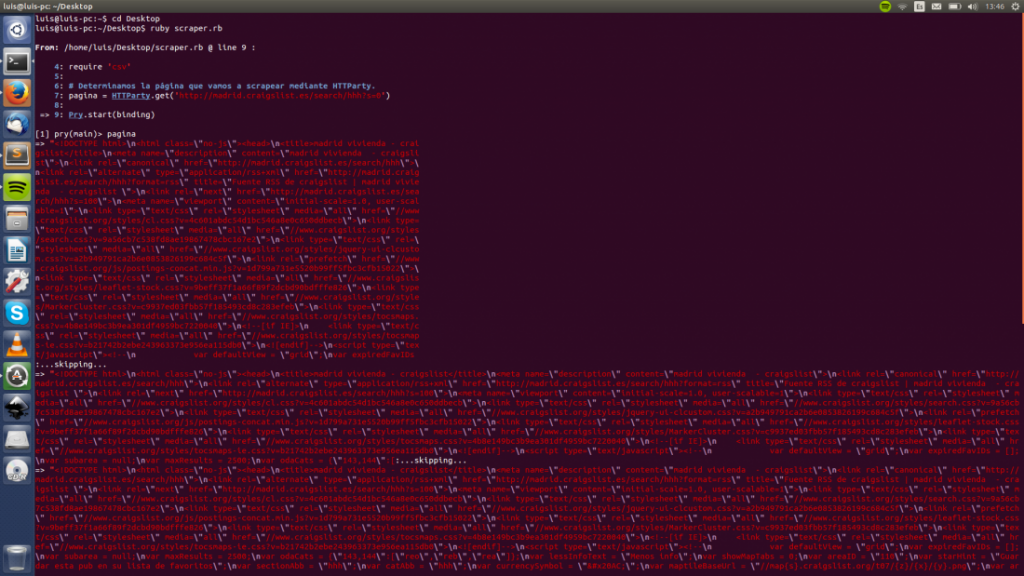
Interesante ¿verdad? Hemos accedido a un sitio web sin usar un navegador como Firefox o Chrome, sino mediante un programa que hemos escrito nosotros mismos.
Nogokiri
Ahora, utilizaremos Nokogiri para transformar todo el código HTML que hemos obtenido en un objeto y poder manipularlo fácilmente. Para ello creamos una nueva variable llamada «pagina_Nokogiri» y le asignamos el valor del método que convierte código HTML en un objeto Nokogiri. Dejad la llamada a Pry al final.
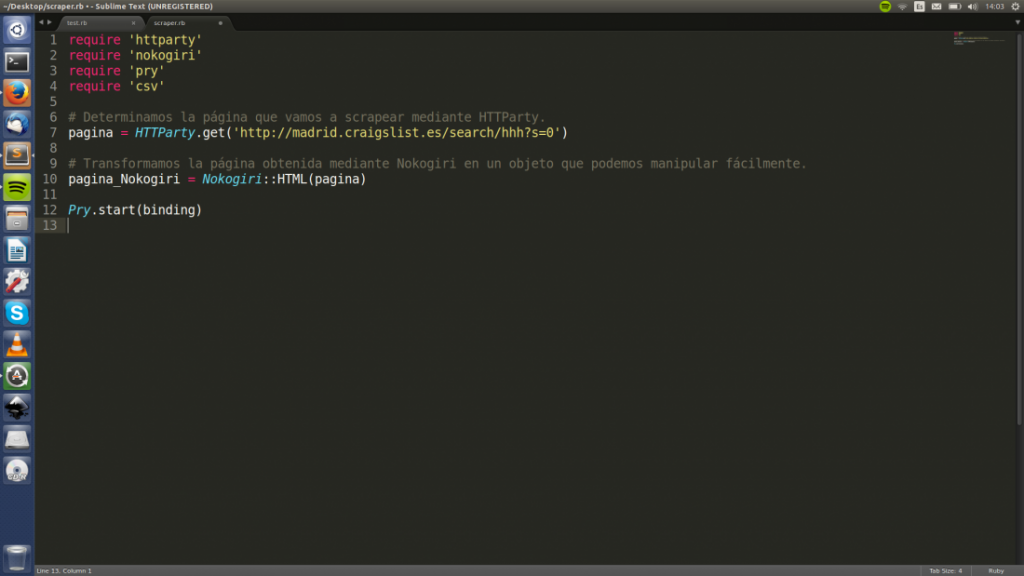
Acto seguido volvemos a ejecutar nuestro scraper.rb. Pry volverá a ejecutarse pero esta vez escribiremos el nombre de nuestra nueva variable «pagina_Nokogiri» lo que imprimirá algo similar a esto:
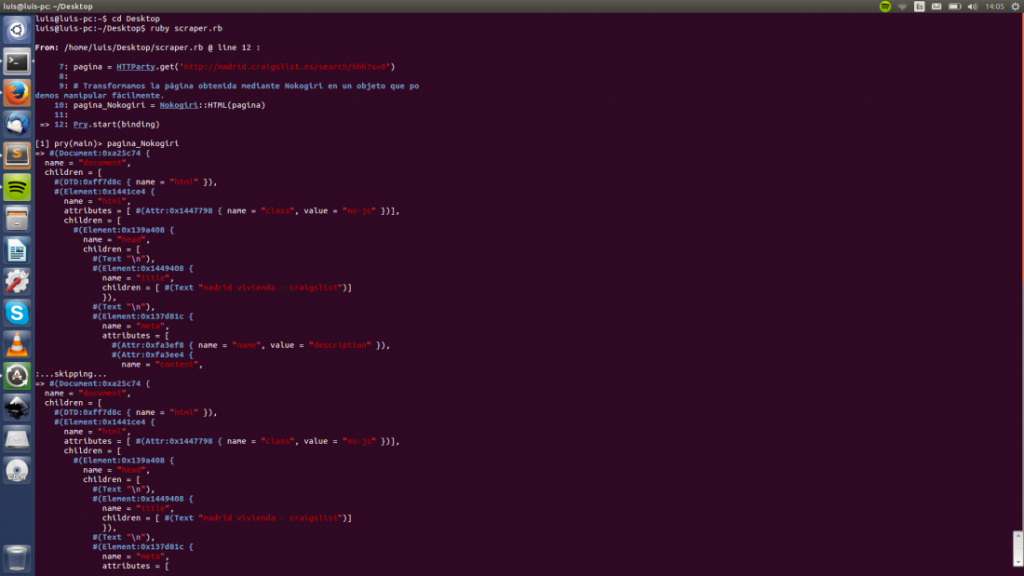
Una buena práctica es crear un nuevo documento y copiar el código HTML obtenido mediante Nokogiri, ya que será de utilidad más adelante.
Estructurando la Información
En primer lugar creamos un nuevo array llamado «array_Pisos» en el que introduciremos los datos obtenidos de nuestro scraping para posteriormente pasarlos a una hoja de cálculo, por lo que lo mantendremos vacío por el momento.
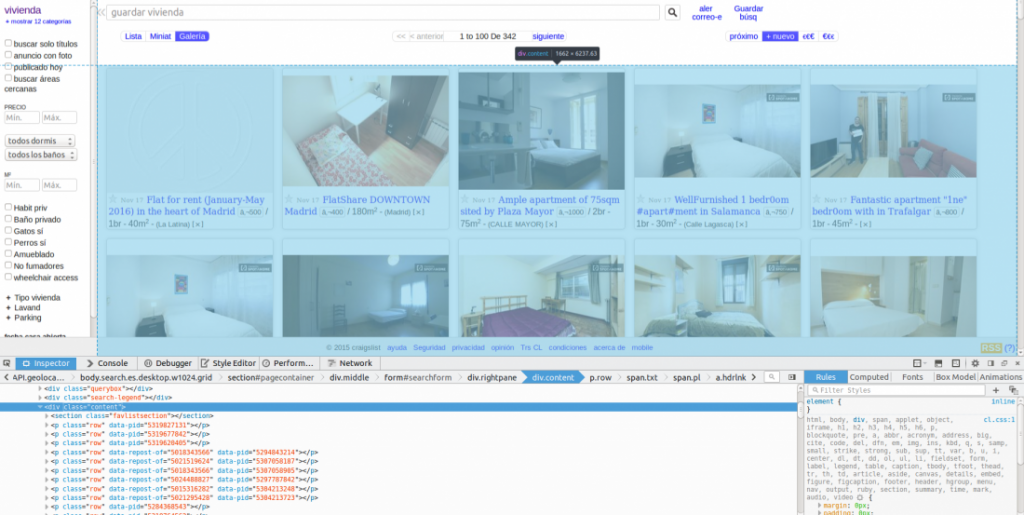
 Ya tenemos todo listo para empezar a trabajar. Nuestro objetivo es encontrar un patrón común en todos los títulos de los anuncios, para lo que utilizaremos la función «inspeccionar elemento» de nuestro navegador. El documento HTML que guardamos hace un momento, la función «ver código fuente» o incluso el propio Pry nos pueden servir para esto, es sólo cuestión de gustos.
Ya tenemos todo listo para empezar a trabajar. Nuestro objetivo es encontrar un patrón común en todos los títulos de los anuncios, para lo que utilizaremos la función «inspeccionar elemento» de nuestro navegador. El documento HTML que guardamos hace un momento, la función «ver código fuente» o incluso el propio Pry nos pueden servir para esto, es sólo cuestión de gustos.
Tras echarle un vistazo al codigo de la página vemos como los anuncios están dentro de un div donde class=”content”.
Cada anuncio se encuentra dentro de de un class='»row»
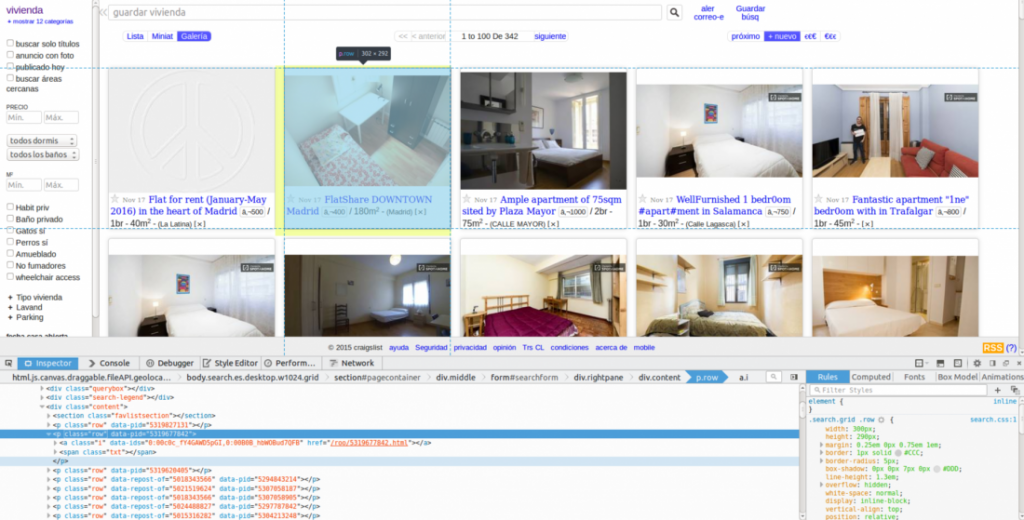
Y cada texto se encuentra dentro de un anchor tag (<a></a>) donde class=”hdrlnk”.
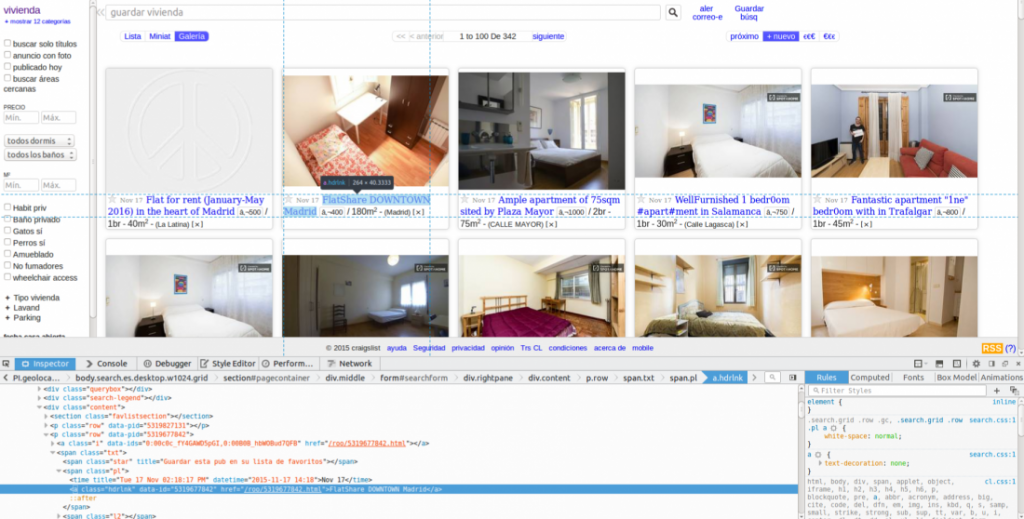
Tan simple como hacer click derecho sobre el elemento en que buscamos scrapear y darle un poco al coco 😁.
Ahora tenemos que indicarle a Nokogiri que extraiga los textos y los introduzca en el reluciente array que acabamos de crear para finalmente poder exportarlo todo a una hoja de cálculo. Para ello utilizaremos dos métodos de Ruby: .text y .map.
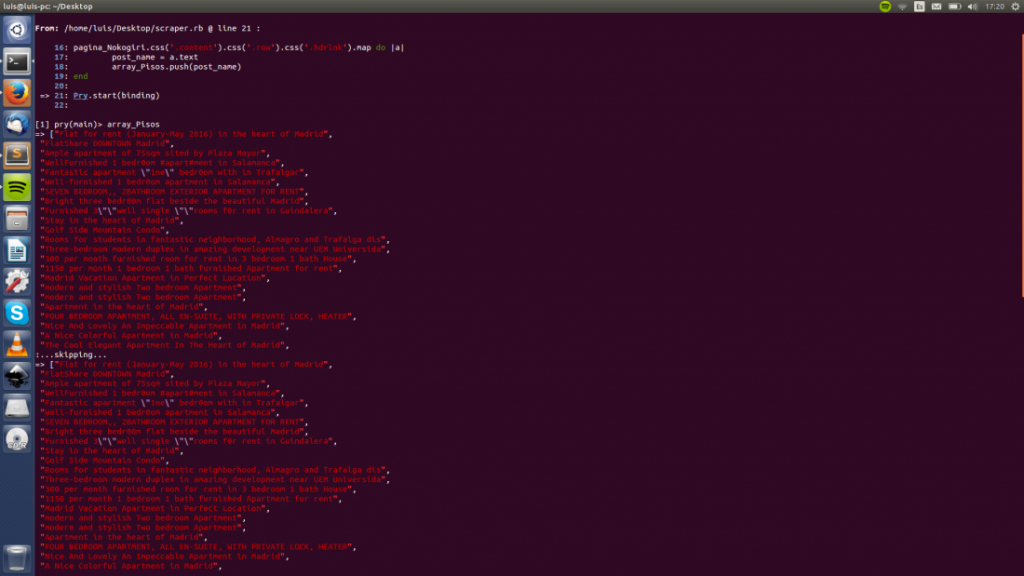
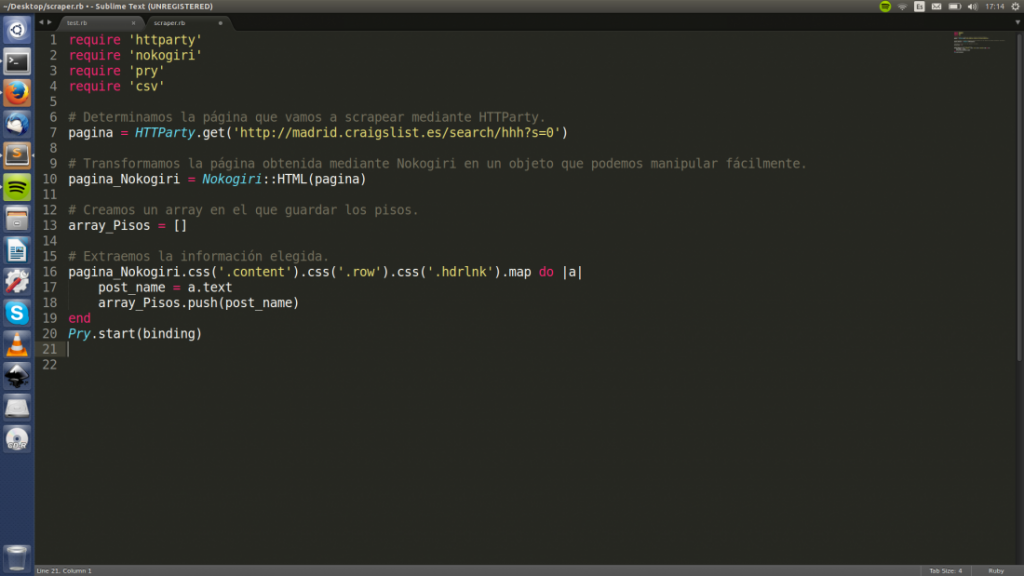 Guarda el fichero y ejecútalo en la terminal, acto seguido abre el array que creamos al principio de este punto. (array_pisos) y verás tu preciosa lista de pisos lista para exportar.
Guarda el fichero y ejecútalo en la terminal, acto seguido abre el array que creamos al principio de este punto. (array_pisos) y verás tu preciosa lista de pisos lista para exportar.
Exportar a un CSV
¡Enhorabuena! Has llegado al último paso. Sólo nos falta copiar toda la información a un CSV para poder manipular fácilmente la información scrapeada. Para ello añadid las siguientes lineas de código a vuestro programa.
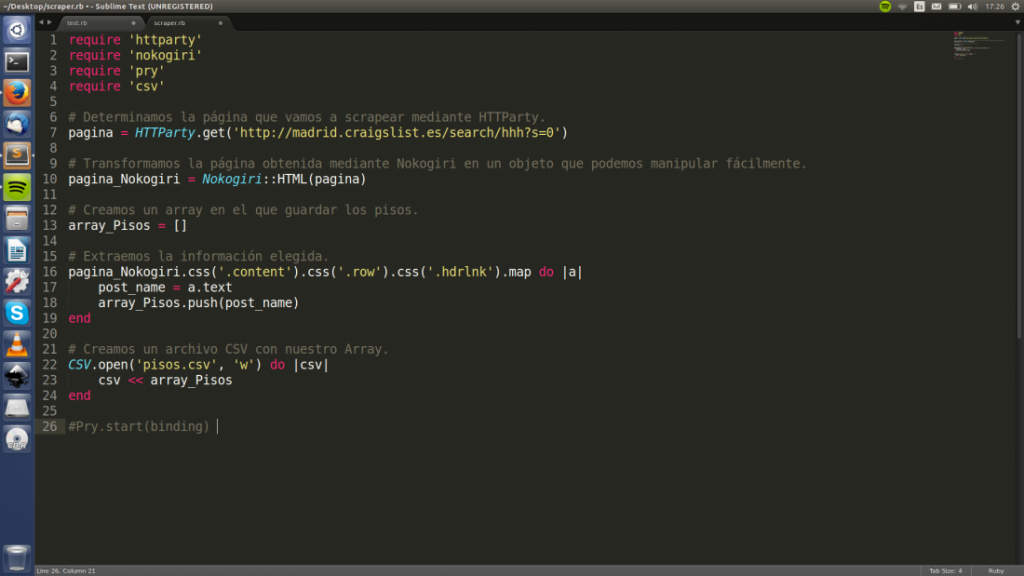
Básicamente creamos un nuevo fichero .csv llamado «pisos.csv» con permisos de escritura (de ahí viene la ‘w’) y le asignamos el contenido de «array_Pisos». ¡Voilà! Hemos terminado nuestro primer scraper 🎉🎉🎉.
Conclusiones Finales
Hemos conseguido acceder a una web, obtener información estructurada y exportarla a un formato de fácil manejo como puede ser una hoja de cálculo. Nada mal ¿verdad?
A partir de este punto podemos hacer muchas cosas. Podríamos crear un nuevo objeto que incluyera otros atributos además del título e incluir la descripción y las características de cada inmueble. Otra opción sería utilizar un par de bucles while() para no limitarnos a una sola página, sino decenas.
El límite, como siempre, es vuestra imaginación y el tiempo y esfuerzo que le dediquéis.
Implicaciones Legales
Es decir, el web scraping consiste en utilizar un programa (programado o no por nosotros) para extraer cierta información de una página web propia o ajena, es indiferente. Sueno un poco chungo ¿no? Quizá incluso rozar el límite de la legalidad.
Si el scraping es legal es un tema sobre el que podría escribir otro (o varios) artículos más, ya que no hay nada claro. El mismísimo Google (y cientos de empresas) scrapean constantemente la web con sus arañitas, sin embargo no parecen tener problemas legales con ello. Lo único claro es que lo más importante es el uso que le des a la información extraída.
Así que ya sabéis, ¡andaros con ojo!
Limitaciones Técnicas
Existen varias limitaciones que nos impiden scrapear todo lo que deseemos con este método.
En primer lugar tenemos que tener en cuenta las limitaciones técnicas del hardware de nuestra máquina y nuestra conexión a internet. No creo que se dé el caso, ya que este es un tutorial extremadamente básico y cualquier pc puede ejecutar este pequeño programa. Sin embargo, proyectos a gran escala necesitarán máquinas y conexiones mucho más potentes.
Como ya comenté en la introducción del artículo, Nokogiri tiene ciertas limitaciones técnicas también. Sólo podremos scrapear contenido que sea cargado del lado del servidor. Por ejemplo, si parte del contenido de una página es cargado usando Ajax nos será imposible acceder a él.
La seguridad del sitio también es un punto a tener en cuenta, ya que si queremos acceder a contenido protegido por contraseña lo tendremos bastante difícil a no ser que saquemos el hacker black hat que llevamos dentro 😈.
¿Qué hago a continuación?
Si os ha molado el artículo tengo un par de ideas bastante interesantes que ampliarán el contenido básico de esta guía introductoria. Si no podéis esperar (con lo que tardo en escribir me parece normal) y queréis poneros a scrapear toda la red os recomiendo echarle un vistazo a Spooky.js (Javascript) y Pyquery (Python).
Si queréis seguir profundizando en el web scraping con Ruby echadle un ojo a Mechanize. Esta gem nos permite rellenar formularios, descargar contenido del sitio y imitar el comportamiento de un usuario real, con lo que podremos hacer verdaderas virguerías.
Y esto es todo por hoy, hacedme saber qué os ha parecido en los comentarios✌️.
¡Genialérrimo artículacho! 😁👍
¡Muchas gracias Loren!
A darle caña al scraping 😁.
Muy buenas, enhorabuena por tu web y por este artículo en particular.
Necesito entrar en una web con usuario y contraseña (que poseo por supuesto) y según unos datos que introduzca en el formulario me muestre una información y conseguir acceder a ella de manera práctica ya que lo haría con muchos registros.
¿alguna idea de por donde comenzar?
Gracias!